Engineering Guidelines
This topic describes the technical set up for the Zusammen performance test, the test method that was followed, and the test results.
The technical stack can be found in the Installation Guide.
Performance
Using ~50KB files
Deployment architecture
VM Spec
| Name | Value |
|---|---|
| OS | Ubuntu |
| CPU | 2 vCPUs |
| RAM | 4 GB |
Test Plan
We have tested three scenarios:
- A single branch and a server with a single repository.
- A single branch and a server with hundreds of repositories (500).
- Three branches in a round-robin, and a server with a single repository.
The number of loops was set to 1500 per branch.
For each scenario, we performed the following test plan:
- Push latency
- For both repos
- Clone repo
- Loop N times
- Write to file
- Change and flush file
- Commit
- Start timer
- Push
- Stop timer
- FF merge latency
- For both repos
- Clone repo
- Open file in each repo
- Loop N times
- Write to file in both repos
- Flush files
- Commit
- Pull in repo A
- Push in repo A
- Start timer
- Pull in repo B
- Push in repo B
- Stop timer
- Pull latency
- For both repos
- Clone repo
- Open file in each repo
- Loop N times
- Write to file in both repos
- Flush files
- Commit
- Push in repo A
- Start timer
- Pull in repo B
- Stop timer
KPIs
Our tests checked the operation amortized time (without network latency, using loop back).
Test method
We selected jMeter as our test runner, then wrote Java 8 jMeter actions and used the jMeter timing mechanism to time the interesting part of the function (see the test plan for details).
In the single branch scenario, we ran the test 1500 times.
In the scenario with three branches, we ran the test 4500 times (1500 per branch) and took the average of three calls.
Test results
These are the results of our performance tests.
Push
Stats
| 1 branch, 1 repo | 3 branches, 1 repo | 1 branch, 500 repo | |
|---|---|---|---|
| AVG (ms) | 53.8 | 54.7 | 54 |
| Median (ms) | 53 | 53 | 53 |
Graph
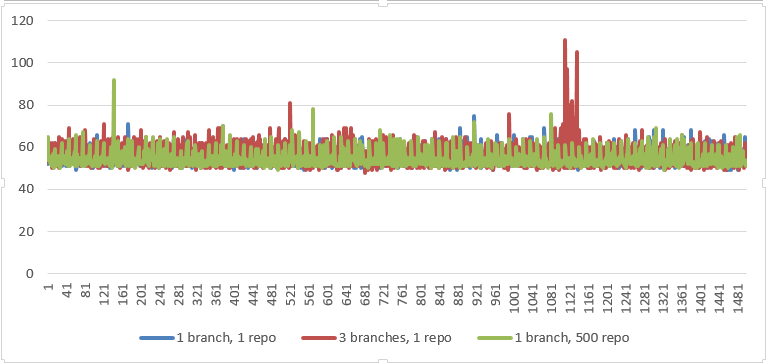
Pull
Stats
| 1 branch, 1 repo | 3 branches, 1 repo | 1 branch, 500 repo | |
|---|---|---|---|
| AVG (ms) | 114.4 | 114.9 | 114.4 |
| Median (ms) | 111 | 112 | 110 |
Graph
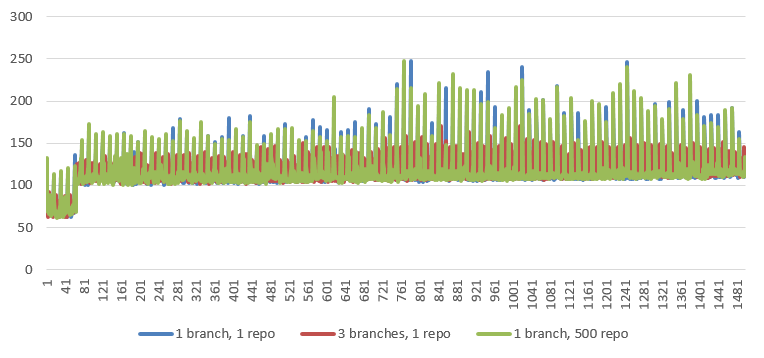
Merge
Stats
| 1 branch, 1 repo | 3 branches, 1 repo | 1 branch, 500 repo | |
|---|---|---|---|
| AVG (ms) | 132.7 | 132.7 | 133.6 |
| Median (ms) | 127 | 127 | 128 |
Graph
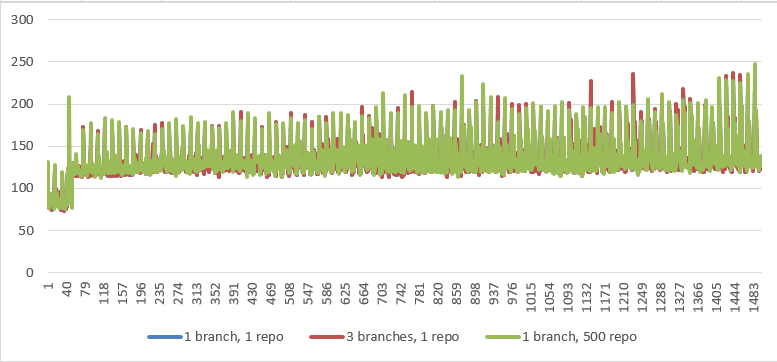
Scaling Practices
Zusammen
Zusammen is a Java library and should be scaled with the host application.
Search index - Elastic
For High Availability or Geographic Redundancy, Elastic should be installed on at least two nodes at each site.
Each node should have 32GB of RAM, and two to eight cores.
Highly Recommended: Configure Elastic to have at least two shards (five is preferred). This enables easy horizontal scaling when the need arises.
Monitor load and cluster health in Elastic, and use the health information for scaling and healing.
When an Elastic cluster or node heap is overused over a long period, the administrator should spawn additional nodes (pre-defined sharding is helpful here).
Metadata store - Cassandra
Cassandra handles the expected load easily, but, to be safe, it should be monitored and scaled if needed. Zusammen is designed with a scale-ready partition key.
Cassandra scaling is achieved by adding nodes to the cluster, with Cassandra itself managing replication to additional nodes.
Collaboration aware store - Git
Git has a very small footprint for most operations. However, pull and clone are both very CPU intensive because of heavy compression processes during packing.
Your initial Git setup should be a multi-core CPU with a fast, highly available network mount. For example, a highly available Network File System (NFS).
In most cases, a single Git server will be enough for a very large number of concurrent users (circa one thousand). This is because user activity with Git will be once every few seconds at a random frequency.
The Git server should be monitored for the most common telemetrics (CPU, HDD space, used MEM, and so on). If monitoring suggests a need to scale up, a new Git server should be spawned that uses the same repository as its store. You may use any Git server implementation.
There should be a load balancer before the Git servers.
If there is a lack of storage space, the storage administrator should allocate more disk space.